

DeepSeek是一家开荒于2023年的公司日本av,以其编削的开源期间挑战逾越AI厂商而闻明,最近发布了全新超大型模子:DeepSeek-V3。

新模子通过公司许可公约在Hugging Face上发布,领有6710亿参数,并经受民众羼杂架构(Mixture-of-Experts),以激活特定参数,从而高效准确地解决指定任务。
笔据DeepSeek发布的基准测试抑制,该模子在性能名次榜上已处于逾越地位,超过了包括Meta的Llama 3.1-405B在内的顶级开源模子,并接近Anthropic和OpenAI的闭源模子的性能。
DeepSeek-V3的上风是什么?
与其前身DeepSeek-V2近似,这款超大型模子经受以多头潜在闪耀力(MLA)和DeepSeekMoE为中枢的基础架构。
萝莉抖音这种顺序保证了高效的考研和推感性能,通过激活6710亿参数中的370亿参数(由模子内的独处或分享“民众”——更小的神经网罗已毕),擢升任务后果。
DeepSeek-V3的两项首要编削
1. 无扶助亏欠的负载均衡计谋: 动态监控并转机民众的负载日本av,确保均衡使用,同期不影响模子全体性能。
2. 多象征瞻望(MTP): 允许模子同期瞻望多个将来象征,擢升考研后果,使模子每秒生成60个象征,比以往快3倍。
考研后果与本钱
在预考研历程中,DeepSeek-V3使用了14.8万亿高质料象征数据,并通过两个阶段将高下文长度彭胀至32K和128K。
后期考研阶段包括监督微调(SFT)和强化学习(RL),以使模子更贴合东说念主类偏好。
考研历程中经受了硬件和算法优化期间,如FP8羼杂精度框架和DualPipe活水线并行算法。
悉数这个词考研花费约278.8万小时的H800 GPU推断时期,本钱约为557万好意思元,远低于频繁考研近似大型谈话模子所需的数亿好意思元。
基准测试进展
尽管考研本钱较低,DeepSeek-V3仍成为现在最强的开源模子。
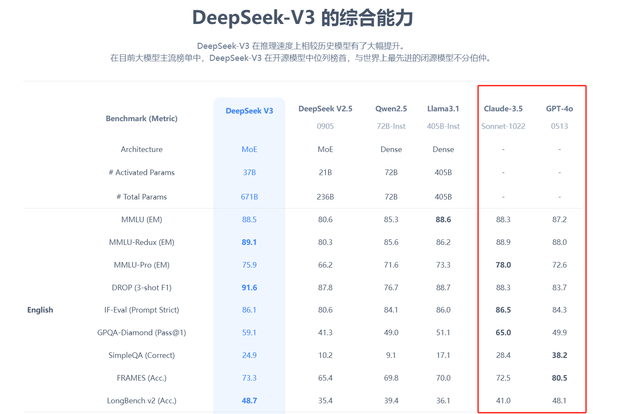
它超过了Llama-3.1-405B和Qwen 2.5-72B,并在大多量基准测试中打败了GPT-4o,但在以英语为主的SimpleQA和FRAMES测试中进展稍逊一筹。
DeepSeek-V3在中语和数学基准测试中进展尤为杰出,如Math-500测试中,它的得分为90.2,而Qwen仅为80。
开源对AI行业的影响
DeepSeek-V3标明开源模子正在赶上闭源系统,在多个任务中提供接近的性能进展。
这一进展对行业成心,因为它不容了附近,并为企业提供了构建AI系统的多种选拔。
取得表情与订价
DeepSeek-V3在GitHub上以MIT许可发布,模子自己则以公司许可提供。企业可通过DeepSeek Chat或API进行测试。
从2025年2月8日起,API用度为每百万输入象征0.27好意思元(有缓存射中时为0.07好意思元)日本av,每百万输出象征1.10好意思元。


